By: W15-3 Since: Feb 2019 Licence: MIT
1. Setting up
1.1. Prerequisites
-
JDK
9or laterJDK 10on Windows will fail to run tests in headless mode due to a JavaFX bug. Windows developers are highly recommended to use JDK9. -
IntelliJ IDE
IntelliJ by default has Gradle and JavaFx plugins installed.
Do not disable them. If you have disabled them, go toFile>Settings>Pluginsto re-enable them.
1.2. Setting up the project in your computer
-
Fork this repo, and clone the fork to your computer
-
Open IntelliJ (if you are not in the welcome screen, click
File>Close Projectto close the existing project dialog first) -
Set up the correct JDK version for Gradle
-
Click
Configure>Project Defaults>Project Structure -
Click
New…and find the directory of the JDK
-
-
Click
Import Project -
Locate the
build.gradlefile and select it. ClickOK -
Click
Open as Project -
Click
OKto accept the default settings -
Open a console and run the command
gradlew processResources(Mac/Linux:./gradlew processResources). It should finish with theBUILD SUCCESSFULmessage.
This will generate all resources required by the application and tests. -
Open
MainWindow.javaand check for any code errors-
Due to an ongoing issue with some of the newer versions of IntelliJ, code errors may be detected even if the project can be built and run successfully
-
To resolve this, place your cursor over any of the code section highlighted in red. Press ALT+ENTER, and select
Add '--add-modules=…' to module compiler optionsfor each error
-
-
Repeat this for the test folder as well (e.g. check
HelpWindowTest.javafor code errors, and if so, resolve it the same way)
1.3. Verifying the setup
-
Run the
seedu.address.MainAppand try a few commands -
Run the tests to ensure they all pass.
1.4. Configurations to do before writing code
1.4.1. Configuring the coding style
This project follows oss-generic coding standards. IntelliJ’s default style is mostly compliant with ours but it uses a different import order from ours. To rectify,
-
Go to
File>Settings…(Windows/Linux), orIntelliJ IDEA>Preferences…(macOS) -
Select
Editor>Code Style>Java -
Click on the
Importstab to set the order-
For
Class count to use import with '*'andNames count to use static import with '*': Set to999to prevent IntelliJ from contracting the import statements -
For
Import Layout: The order isimport static all other imports,import java.*,import javax.*,import org.*,import com.*,import all other imports. Add a<blank line>between eachimport
-
Optionally, you can follow the UsingCheckstyle.adoc document to configure Intellij to check style-compliance as you write code.
1.4.2. Updating documentation to match your fork
After forking the repo, the documentation will still have the SE-EDU branding and refer to the se-edu/addressbook-level4 repo.
If you plan to develop this fork as a separate product (i.e. instead of contributing to se-edu/addressbook-level4), you should do the following:
-
Configure the site-wide documentation settings in
build.gradle, such as thesite-name, to suit your own project. -
Replace the URL in the attribute
repoURLinDeveloperGuide.adocandUserGuide.adocwith the URL of your fork.
1.4.3. Setting up CI
Set up Travis to perform Continuous Integration (CI) for your fork. See UsingTravis.adoc to learn how to set it up.
After setting up Travis, you can optionally set up coverage reporting for your team fork (see UsingCoveralls.adoc).
| Coverage reporting could be useful for a team repository that hosts the final version but it is not that useful for your personal fork. |
Optionally, you can set up AppVeyor as a second CI (see UsingAppVeyor.adoc).
| Having both Travis and AppVeyor ensures your App works on both Unix-based platforms and Windows-based platforms (Travis is Unix-based and AppVeyor is Windows-based) |
1.4.4. Getting started with coding
When you are ready to start coding,
-
Get some sense of the overall design by reading Section 2.1, “Architecture”.
-
Take a look at [GetStartedProgramming].
2. Design
2.1. Architecture
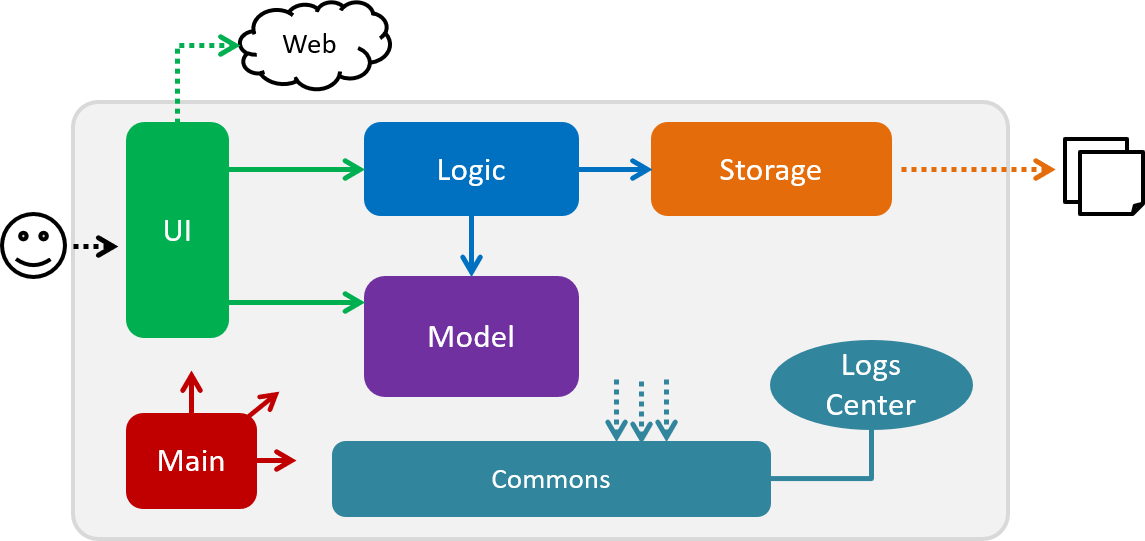
The Architecture Diagram given above explains the high-level design of the App. Given below is a quick overview of each component.
The .pptx files used to create diagrams in this document can be found in the diagrams folder. To update a diagram, modify the diagram in the pptx file, select the objects of the diagram, and choose Save as picture.
|
Main has only one class called MainApp. It is responsible for,
-
At app launch: Initializes the components in the correct sequence, and connects them up with each other.
-
At shut down: Shuts down the components and invokes cleanup method where necessary.
Commons represents a collection of classes used by multiple other components.
The following class plays an important role at the architecture level:
-
LogsCenter: Used by many classes to write log messages to the App’s log file.
The rest of the App consists of four components.
Each of the four components
-
Defines its API in an
interfacewith the same name as the Component. -
Exposes its functionality using a
{Component Name}Managerclass.
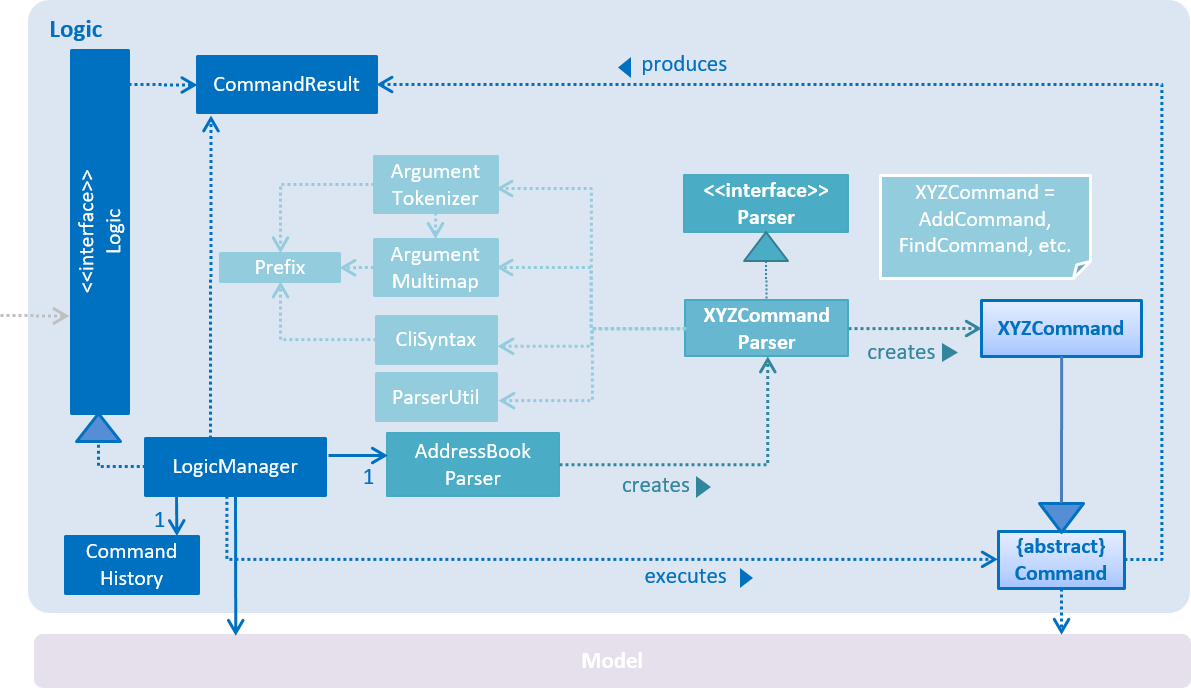
For example, the Logic component (see the class diagram given below) defines it’s API in the Logic.java interface and exposes its functionality using the LogicManager.java class.
How the architecture components interact with each other
The Sequence Diagram below shows how the components interact with each other for the scenario where the user issues the command delete 1.
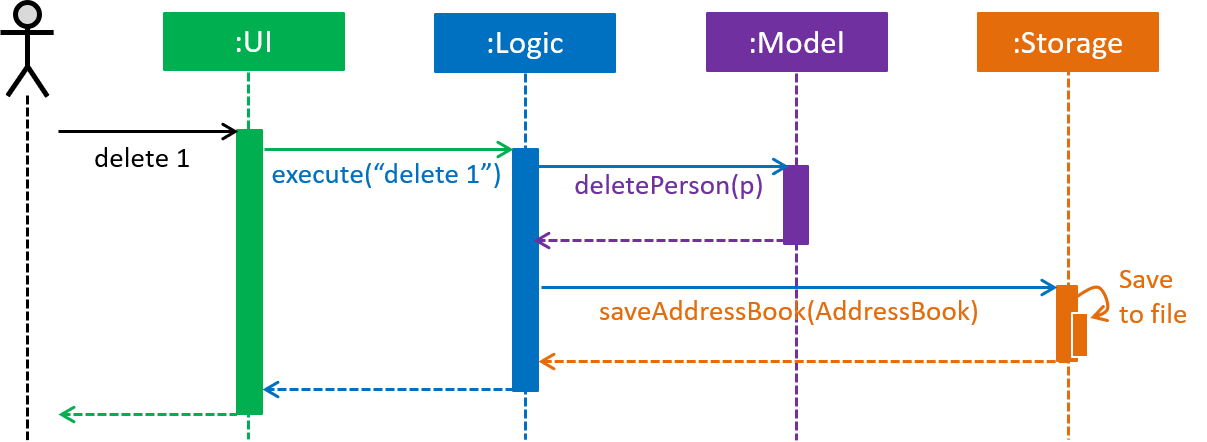
delete 1 commandThe sections below give more details of each component.
2.2. UI component
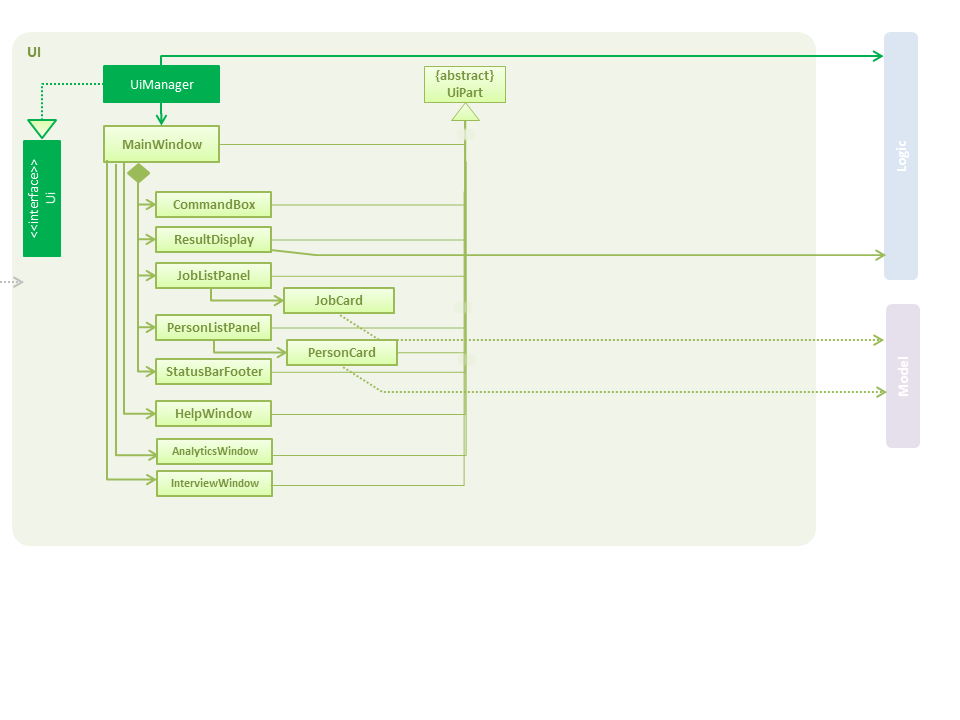
API : Ui.java
The UI consists of a MainWindow that is made up of parts e.g.CommandBox, ResultDisplay, PersonListPanel, StatusBarFooter, JobListPanel etc. All these, including the MainWindow, inherit from the abstract UiPart class.
The UI component uses JavaFx UI framework. The layout of these UI parts are defined in matching .fxml files that are in the src/main/resources/view folder. For example, the layout of the MainWindow is specified in MainWindow.fxml
The UI component,
-
Executes user commands using the
Logiccomponent. -
Listens for changes to
Modeldata so that the UI can be updated with the modified data.
2.3. Logic component
API :
Logic.java
-
Logicuses theAddressBookParserclass to parse the user command. -
This results in a
Commandobject which is executed by theLogicManager. -
The command execution can affect the
Model(e.g. adding a person). -
The result of the command execution is encapsulated as a
CommandResultobject which is passed back to theUi. -
In addition, the
CommandResultobject can also instruct theUito perform certain actions, such as displaying help to the user.
Given below is the Sequence Diagram for interactions within the Logic component for the execute("delete 1") API call.
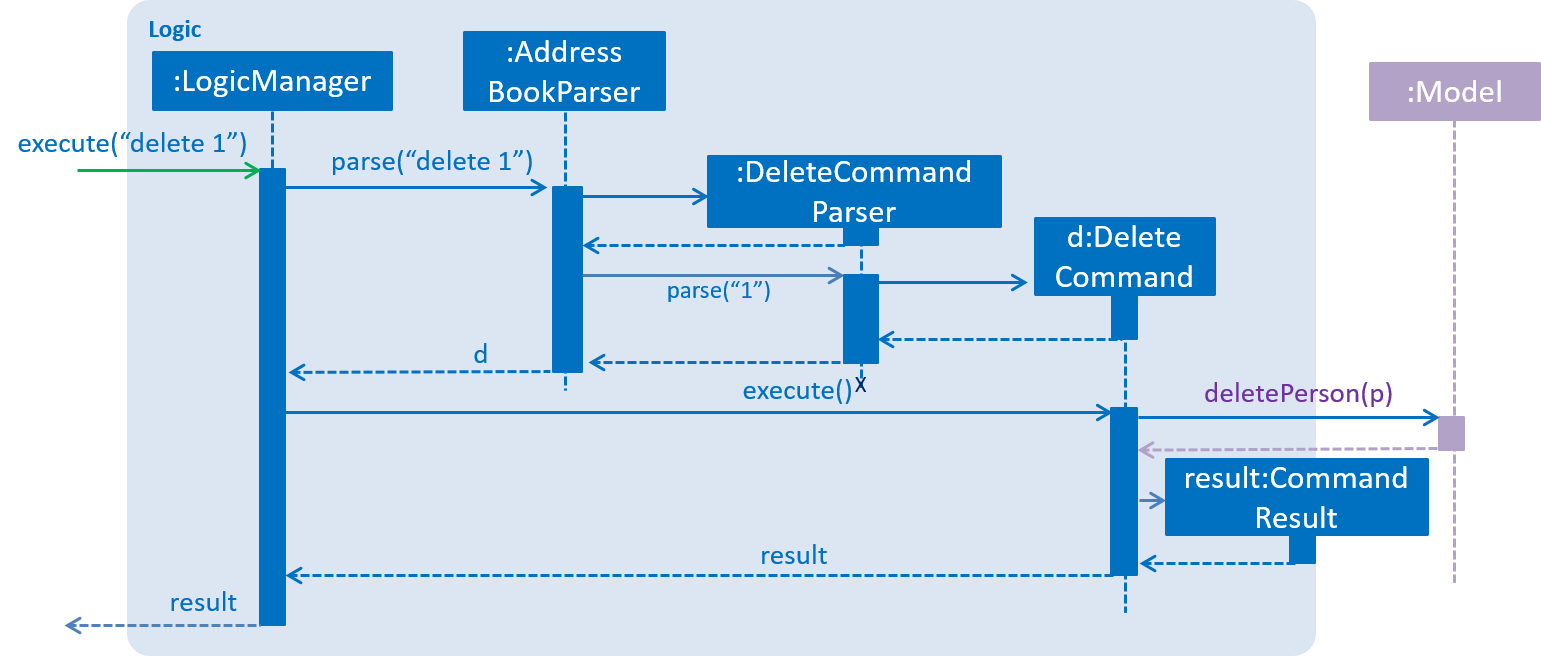
delete 1 Command2.4. Model component
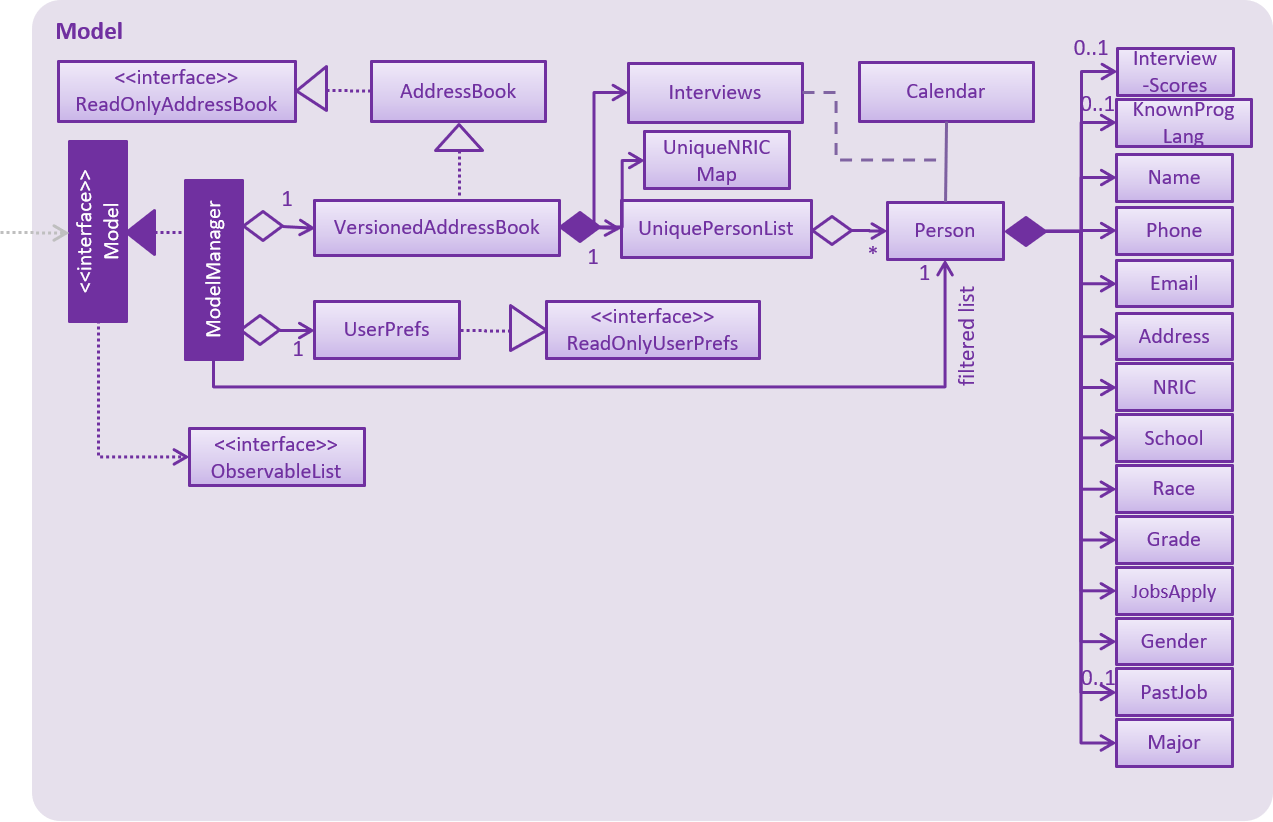
API : Model.java
The Model,
-
stores a
UserPrefobject that represents the user’s preferences. -
stores the Address Book data.
-
exposes an unmodifiable
ObservableList<Person>that can be 'observed' e.g. the UI can be bound to this list so that the UI automatically updates when the data in the list change. -
does not depend on any of the other three components.
-
InterviewScores stores the scores of the applicant and is used in considering an applicant for hiring.
-
NRIC is used as a unique identifier for an applicant.
-
School of the applicant (no restrictions on the input for this).
-
Race and Gender can only take specific values as spelled out in the user guide and it is used in the analytics portion of the app.
-
JobsApply should always be present when a for a person.
-
PastJobs, KnownProgLang and InterviewScores are optional.
-
PastJobs, KnownProgLang and Major stores values as strings therefore, "Engineer, Data Scientist" are stored as one PastJobs.
As a more OOP model, we can store a Tag list in Address Book, which Person can reference. This would allow Address Book to only require one Tag object per unique Tag, instead of each Person needing their own Tag object. An example of how such a model may look like is given below.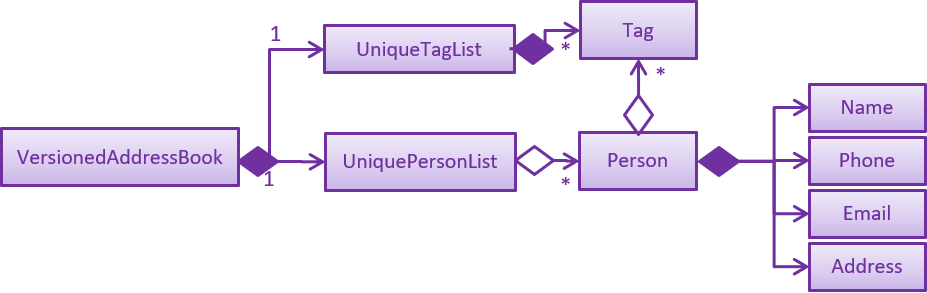
|
2.5. Storage component
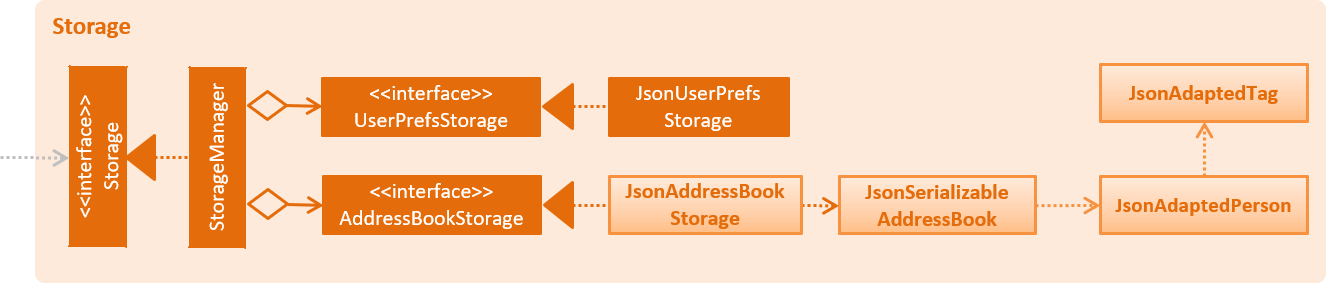
API : Storage.java
The Storage component,
-
can save
UserPrefobjects in json format and read it back. -
can save the Address Book data in json format and read it back.
2.6. Common classes
Classes used by multiple components are in the seedu.addressbook.commons package.
3. Implementation
This section describes some noteworthy details on how certain features are implemented.
3.1. Undo/Redo feature
3.1.1. Current Implementation
The undo/redo mechanism is facilitated by VersionedAddressBook.
It extends AddressBook with an undo/redo history, stored internally as an addressBookStateList and currentStatePointer.
Additionally, it implements the following operations:
-
VersionedAddressBook#commit()— Saves the current address book state in its history. -
VersionedAddressBook#undo()— Restores the previous address book state from its history. -
VersionedAddressBook#redo()— Restores a previously undone address book state from its history.
These operations are exposed in the Model interface as Model#commitAddressBook(), Model#undoAddressBook() and Model#redoAddressBook() respectively.
Given below is an example usage scenario and how the undo/redo mechanism behaves at each step.
Step 1. The user launches the application for the first time. The VersionedAddressBook will be initialized with the initial address book state, and the currentStatePointer pointing to that single address book state.

Step 2. The user executes delete 5 command to delete the 5th person in the address book. The delete command calls Model#commitAddressBook(), causing the modified state of the address book after the delete 5 command executes to be saved in the addressBookStateList, and the currentStatePointer is shifted to the newly inserted address book state.
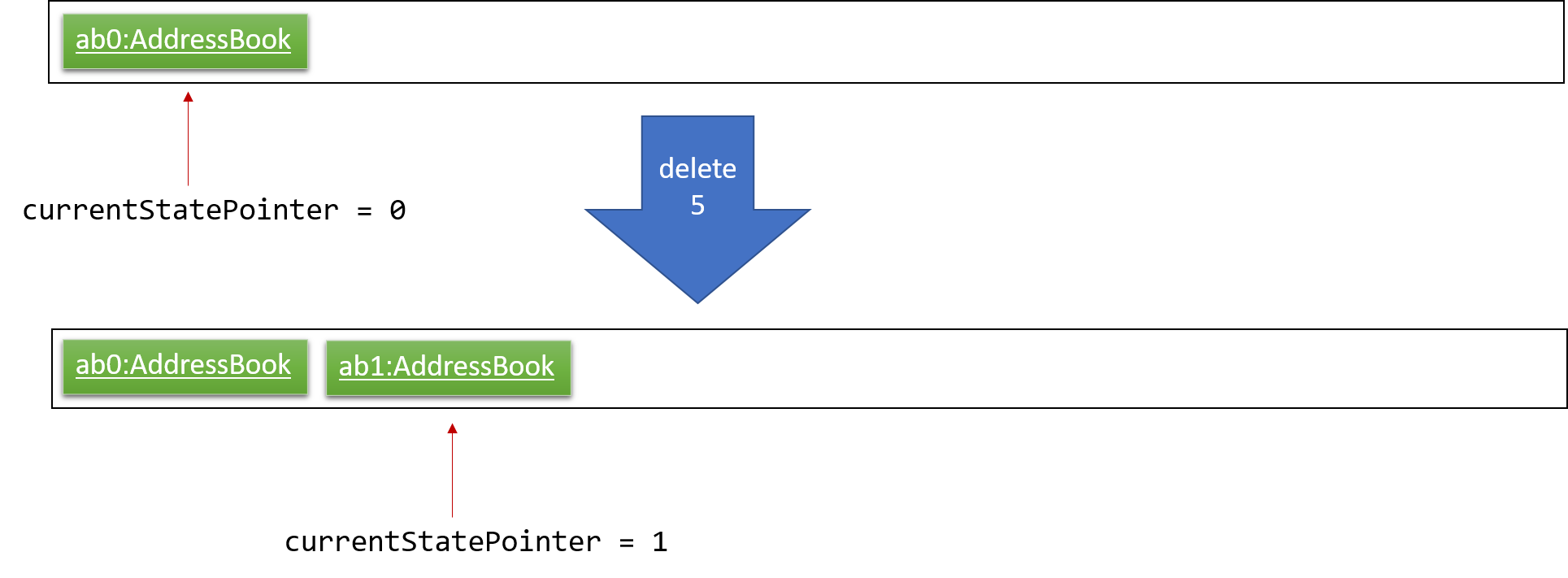
Step 3. The user executes add n/David … to add a new person. The add command also calls Model#commitAddressBook(), causing another modified address book state to be saved into the addressBookStateList.
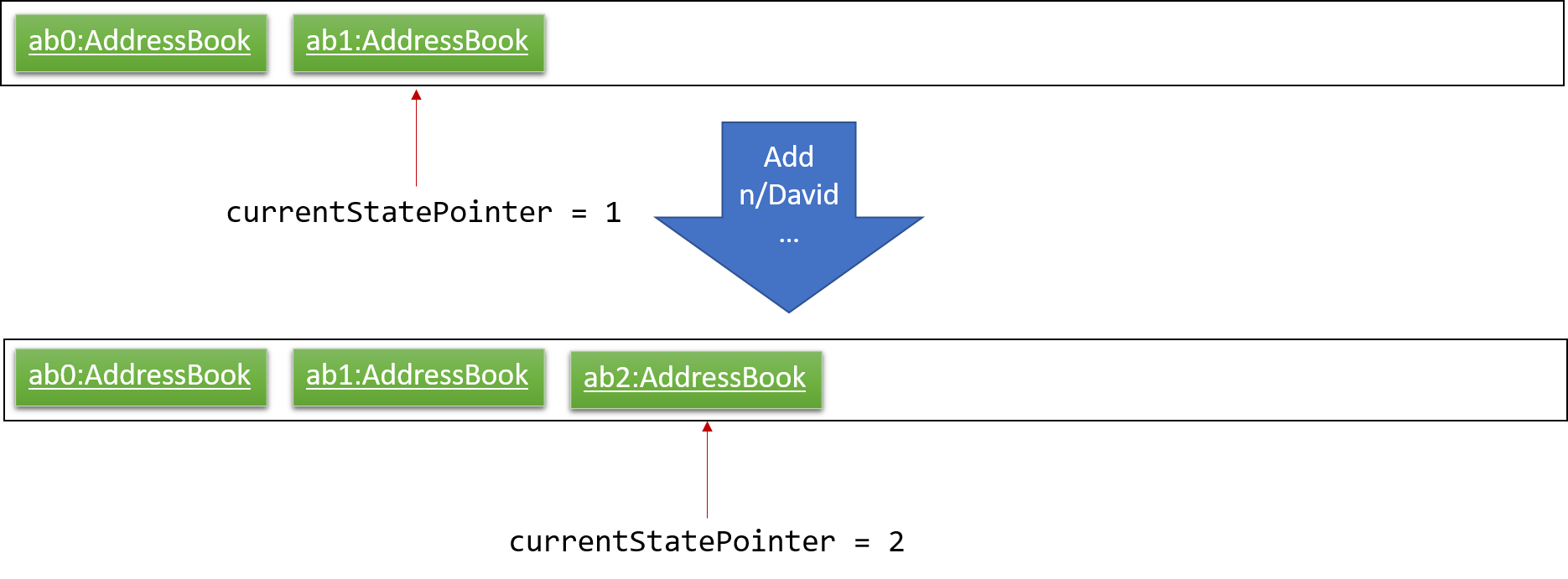
If a command fails its execution, it will not call Model#commitAddressBook(), so the address book state will not be saved into the addressBookStateList.
|
Step 4. The user now decides that adding the person was a mistake, and decides to undo that action by executing the undo command. The undo command will call Model#undoAddressBook(), which will shift the currentStatePointer once to the left, pointing it to the previous address book state, and restores the address book to that state.
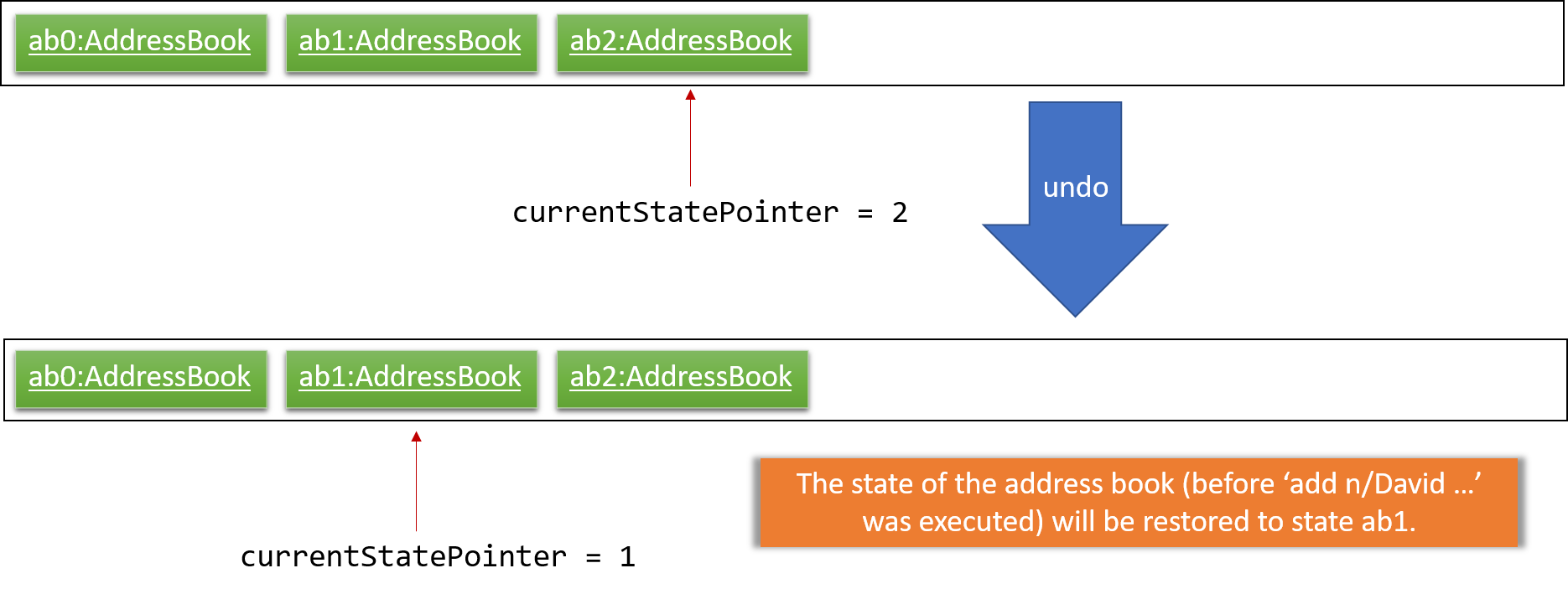
If the currentStatePointer is at index 0, pointing to the initial address book state, then there are no previous address book states to restore. The undo command uses Model#canUndoAddressBook() to check if this is the case. If so, it will return an error to the user rather than attempting to perform the undo.
|
The following sequence diagram shows how the undo operation works:
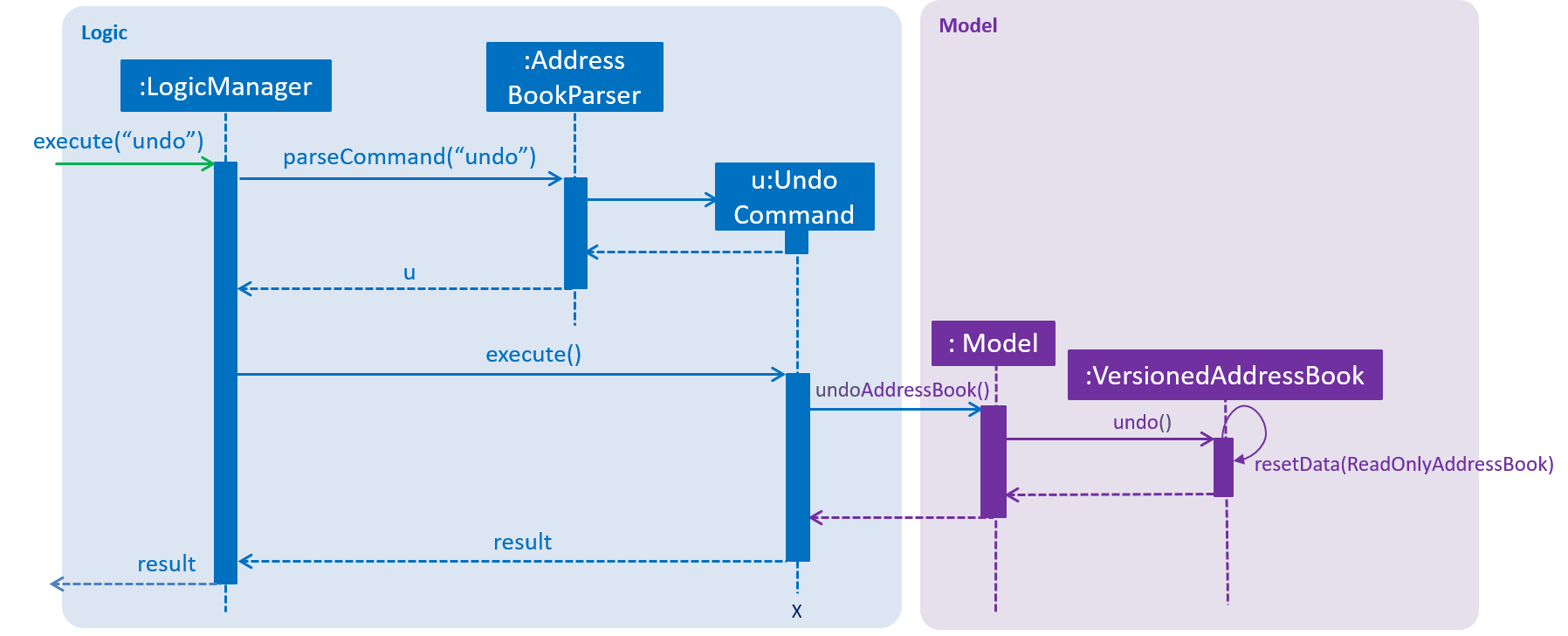
The redo command does the opposite — it calls Model#redoAddressBook(), which shifts the currentStatePointer once to the right, pointing to the previously undone state, and restores the address book to that state.
If the currentStatePointer is at index addressBookStateList.size() - 1, pointing to the latest address book state, then there are no undone address book states to restore. The redo command uses Model#canRedoAddressBook() to check if this is the case. If so, it will return an error to the user rather than attempting to perform the redo.
|
Step 5. The user then decides to execute the command list. Commands that do not modify the address book, such as list, will usually not call Model#commitAddressBook(), Model#undoAddressBook() or Model#redoAddressBook(). Thus, the addressBookStateList remains unchanged.
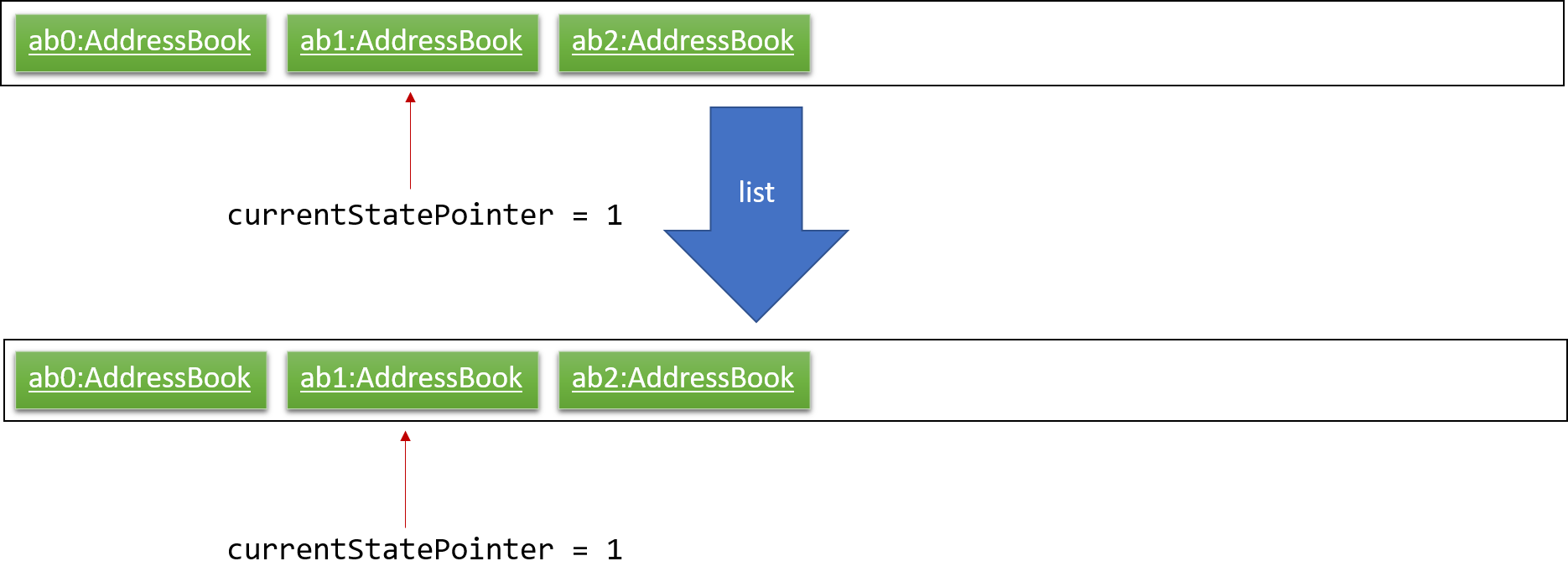
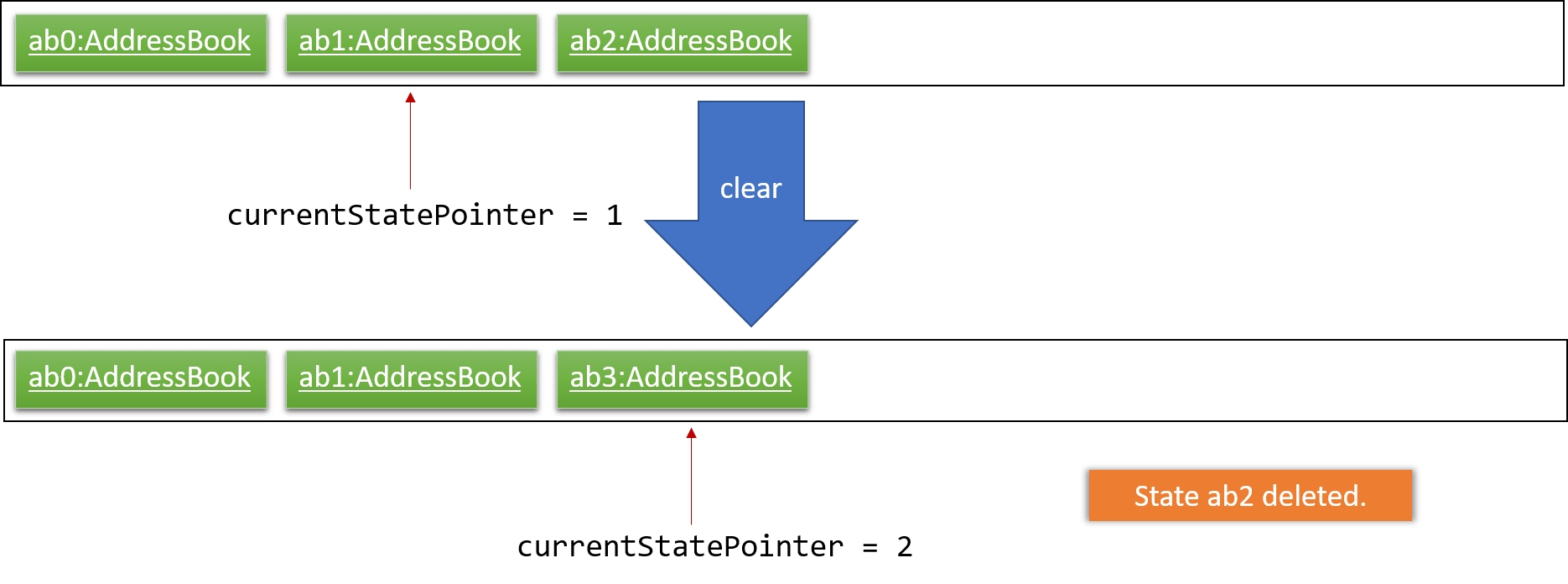
Step 6. The user executes clear, which calls Model#commitAddressBook(). Since the currentStatePointer is not pointing at the end of the addressBookStateList, all address book states after the currentStatePointer will be purged. We designed it this way because it no longer makes sense to redo the add n/David … command. This is the behavior that most modern desktop applications follow.
The following activity diagram summarizes what happens when a user executes a new command:

3.1.2. Design Considerations
Aspect: How undo & redo executes
-
Alternative 1 (current choice): Saves the entire address book.
-
Pros: Easy to implement.
-
Cons: May have performance issues in terms of memory usage.
-
-
Alternative 2: Individual command knows how to undo/redo by itself.
-
Pros: Will use less memory (e.g. for
delete, just save the person being deleted). -
Cons: We must ensure that the implementation of each individual command are correct.
-
Aspect: Data structure to support the undo/redo commands
-
Alternative 1 (current choice): Use a list to store the history of address book states.
-
Pros: Easy for new Computer Science student undergraduates to understand, who are likely to be the new incoming developers of our project.
-
Cons: Logic is duplicated twice. For example, when a new command is executed, we must remember to update both
HistoryManagerandVersionedAddressBook.
-
-
Alternative 2: Use
HistoryManagerfor undo/redo-
Pros: We do not need to maintain a separate list, and just reuse what is already in the codebase.
-
Cons: Requires dealing with commands that have already been undone: We must remember to skip these commands. Violates Single Responsibility Principle and Separation of Concerns as
HistoryManagernow needs to do two different things.
-
3.2. Job Feature
3.2.1. Current Implementation
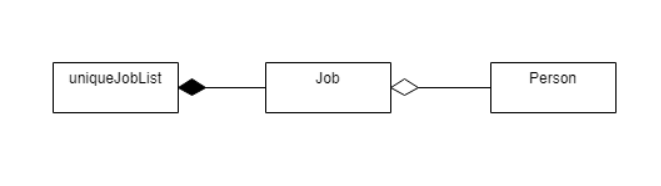
The Job feature is facilitated by the Job class and UniqueJobList Class. UniqueJobList contains Jobs by composition while Jobs contains Person by aggregation. The main Database contains one uniqueJobList which holds all the current job openings.
3.2.2. Storage Implementation
Storage of the Job relies on the JsonAdaptedJob and the JsonAdaptedJobPersonList classes to store and load jobs. Instead of storing a Person in the job, due to the relationship of aggregation, the Nric is stored instead. At load time, the UniqueJobList is only created after the UniquePersonList has been created and fills the jobs using the data from UniquePersonList.
3.2.3. Design considerations
How to associate job with the vanilla AB4 structure
-
Alternative 1 (current choice): Store under addressbook class
-
Pros: Can easily adapt methods of add, delete, undo and redo to work with job
-
Cons: Violates Single responsibility principle as addressbook class now manages both Job and Person data
-
-
Alternative 2: Create an overarching class that contains both addressbook which is a database of Person(s) as well as a Job container class.
-
Pros: Reduced coupling
-
Cons: Implementation of an overarching class would require a major overhaul of current system especially Logic and UI components
-
How to store Person in Job in JSON file
-
Alternative 1 (current choice): Store only one unique person identifier and retrieve person
-
Pros: Saves space extremely significantly by avoiding repeat of data due to many jobs having the same person
-
Cons: When loading, requires more time and violates Law of Demeter as Job class now has access to UniquePersonList which is a class contained in Addressbook
-
-
Alternative 2: Store full person data in Job
-
Pros: Faster loading and adheres to Law of Demeter as the Job does not access more that what it is associated with
-
Cons: Greater memory usage
-
3.3. Filter Feature
With the filter feature, users can input specific parameters that act as conditions for slaveFinder() to conditionally update the UniqueFilterList and filter the UniquePeronList. Using these parameters, slaveFinder() shows applicants contains the specified parameters. Filter is visble and can combine or be deleted.
Command Format:
filter [FILTERLISTNAME] fn/FILTERNAME [<prefix>/<parameter>]…
deleteFilter [FILTERLISTNAME] fn/FILTERNAME
**clearFilter [FILTERLISTNAME]
-
FILTERLISTNAME indicate which Job list this command will used.
3.3.1. Add Filter
The command format for Adding a Filter is:
Format: filter [FILTERLISTNAME] fn/FILTERNAME [n/NAME] pp/PHONE_NUMBER] [nric/NRIC] [e/EMAIL] [a/ADDRESS] [g/GENDER] [r/RACE] [m/MAJOR] [s/SCHOOL] [gr/GRADE] [is1/INTERVIEWSCORESQ1] [is2/INTERVIEWSCORESQ2] [is3/INTERVIEWSCORESQ3] [is4/INTERVIEWSCORESQ4] [is5/INTERVIEWSCORESQ5] [j/JOBS_APPLY]… [kpl/KnowPROGLANG]… [pj/PASTJOB]…
|
Upon entering the filter command, the filter command word is stripped from the input and the argument fields are passed into the FilterCommandParser class. The FilterListName will be stripped from the argument and parse to LISTNAME object. FilterCommandParser tokenizes the other argument string using ArgumentTokenizer object, The regular expressions will be checked and mapping each parameter to it’s respective prefix in an ArgumentMultiMap object. FilterCommandParser then creates a predicatePersonDescriptor object using the parameter
values in ArgumentMultiMap for each filter. If invalid parameters are specified by the user, or if an invalid FILTERLISTNAME was be inputed, or there is no filter name is provided, then FilterCommandParser throws a ParseException and displays an error message to the user.
If valid inputs are provided, predicatePersonDescriptor will be created and FilterCommandParser will return a FilterCommand with parameters predicatePersonDescriptor and FilterName and FilterListName. FilterCommand then creates a Predicate Manager object (implements Java 8’s Predicate interface) using the parameter values in predicatePersonDescriptor for each filter condition, and combines them into one single Predicate using the and() function in Predicate interface. After that, FilterCommand calls the addPredicate method in Model to set the Predicate List (indicated by FilterListName).In the end FilterCommand calls the updateFilteredPersonList method in Model to update applicants using all current undeleted PredicateManager object. UI will change and displaying all undeleted Filter name label and the Person who evaluates the set Predicate to true. If repeated filterName are specified by the user, or if an non-empty FILTERLISTNAME was be inputed in All Job Screen mode, or if no FILTERLISTNAME was be inputed in JOb Detail Screen mode, then FilterCommandParser throws a CommandException and displays an error message to the user.
Current Implementation
The following sequence diagram shows the flow of events when the filter fn/nus command is entered by the user:
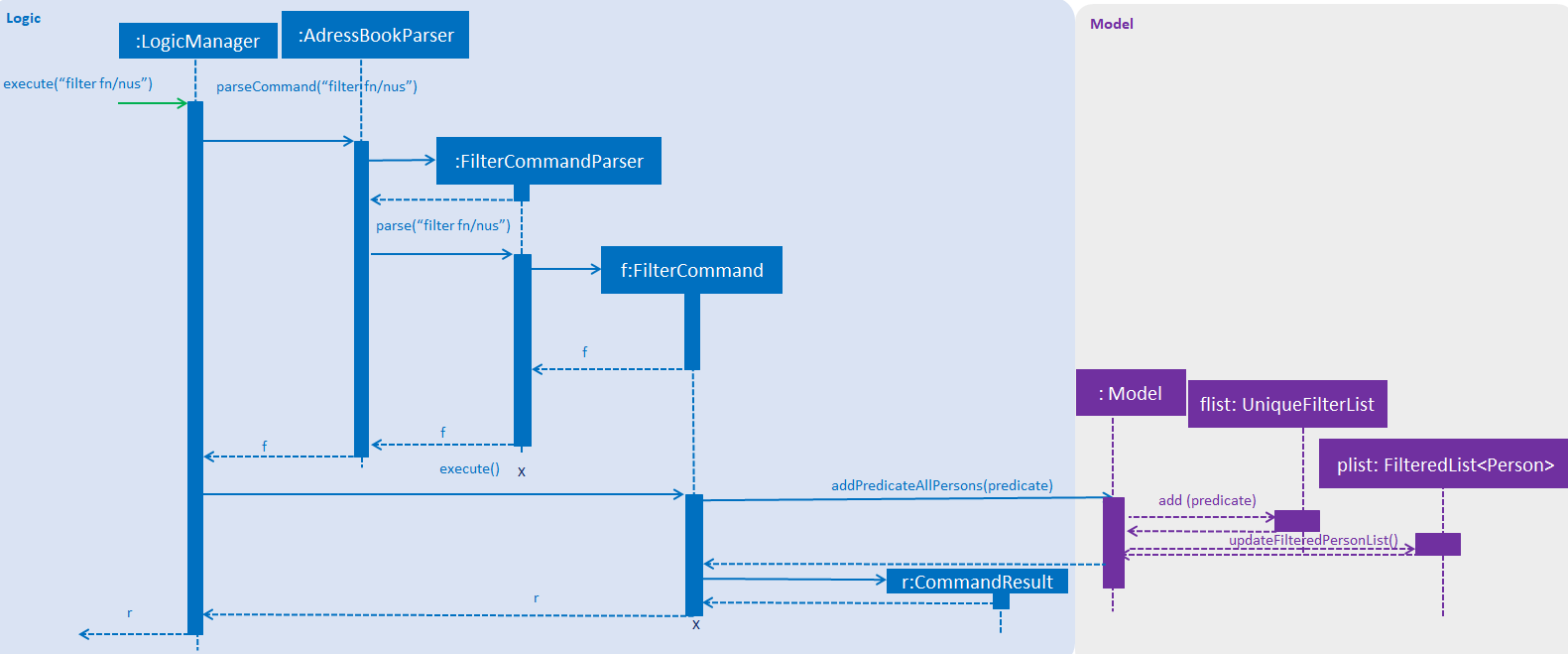
Figure: Sequence diagram illustrating the interactions between the
Logic and Model components when filter command is called.
3.3.2. Delete Filter
The command format for Deleting a filter is:
Format: deleteFilter [FILTERLISTNAME] FILTERNAME
Upon entering the deleteFilter command, the deleteFfilter command word is stripped from the input and the argument fields are passed into the DeleteFilterCommandParser class. The FilterListName will be stripped from the argument and parse to LISTNAME object. DeleteFilterCommandParser tokenizes the FILTERNAME. If an invalid FILTERLISTNAME was be inputed, or there is no filter name is provided, then DeleteFilterCommandParser throws a ParseException and displays an error message to the user.
If valid inputs are provided, DeleteFilterCommandParser will return a DeleteFilterCommand with parameters FilterName and FilterListName. FilterCommand. After that, DeleteFilterCommand calls the removePredicate method in Model to set the Predicate List (indicated by FilterListName).In the end FilterCommand calls the updateFilteredPersonList method in Model to update applicants using all current undeleted PredicateManager object. UI will change and displaying all undeleted Filter name label and the Person who evaluates the set Predicate to true. If no filterName are found, or if an non-empty FILTERLISTNAME was be inputed in All Job Screen mode, or if no FILTERLISTNAME was be inputed in JOb Detail Screen mode, then DeleteFilterCommandParser throws a CommandException and displays an error message to the user.
3.3.3. Clear Filter
The command format for Clearing a filter is:
Format: `clearFilter [FILTERLISTNAME] `
Upon entering the clearFilter command, the clearFfilter command word is stripped from the input and the argument fields are passed into the ClearFilterCommandParser class. The FilterListName will be stripped from the argument and parse to LISTNAME object. ClearFilterCommandParser tokenizes the FILTERNAME. If an invalid FILTERLISTNAME was be inputed, then ClearFilterCommandParser throws a ParseException and displays an error message to the user.
If valid inputs are provided, ClearFilterCommandParser will return a ClearFilterCommand with parameters FilterName and FilterListName. FilterCommand. After that, ClearFilterCommand calls the clearPredicate method in Model to set the Predicate List (indicated by FilterListName).In the end ClearFilterCommand calls the updateFilteredPersonList method in Model to update applicants using an always true PredicateManager object. UI will change and displaying an empty filter panel and the all Persons will show. If an non-empty FILTERLISTNAME was be inputed in All Job Screen mode, or if no FILTERLISTNAME was be inputed in JOb Detail Screen mode, then ClearFilterCommandParser throws a CommandException and displays an error message to the user.
3.3.4. Design Considerations
Aspect: How to parse parameters in filter command
-
Alternative 1 (current choice):
FilterCommandParseCreate apredicatePersonDescriptorobject and parse it toFilterCommand-
Pros:
-
Make filterCommand more comparable. We can compare
predicatePersonDescriptorto say whether two filter Command is same. -
Have better contol on a Filtercommand.
-
-
Cons: Logic is indirect.
-
-
Alternative 2:
FilterCommandParsecombine all conditions (parameters) in a Predicate and parse it toFilterCommand-
Pros: Logic is direct.
-
Cons: Predicate interface is incomparable so this make test more difficult.
-
Aspect: How to design a filter name restricted format
-
Alternative 1 (current choice): Filter name can be any String.
-
Pros:
-
Make Filter name more flexible.
-
A filter may include many information. But user can only see this filter by it’s Filter name label. So it should allow user make a more detailed name for memory and control.
-
-
Cons: Because user can take unpredictable signas their filter name, so it may cause unpredictable bugs.
-
-
Alternative 2: Filter name should only be restricted in the specified format
-
Pros: Easy to control and handle error.
-
Cons: User more need more complicated filter name.
-
Aspect: How to handle filter grade and interview scores
-
Alternative 1 (current choice): Filter parameter become a value range and person’s score in this range will be returned.
-
Pros:
-
Make more sense on filtering value related field.
-
HR manager like to know peron’s score in a range, not exactly in a specified value.
-
-
Cons: May add additional logic and error handling.
-
-
Alternative 2: Same logic as other field
-
Pros: Easy to implement.
-
Cons: HR manager like to know peron’s score in a range, not exactly equal to a specified value.
-
3.4. Analytics Feature
3.4.1. Current Implementation
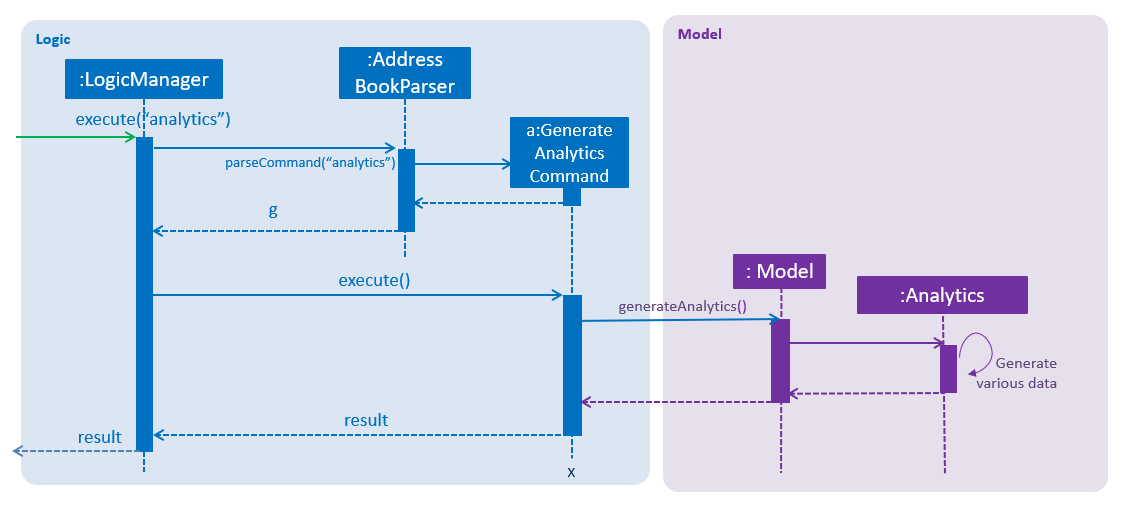
The analytics is facilitated by the Analytics class. Analytics data are generated in real time depending on the specific job currently on display in the software by the user. Hence it will not be saved as states in the versionedAddressBook. It pulls required person list to generate data from Model, which consists of lists: displayedFilter, activeJobAllApplicants, activeJobKiv, activeJobInterview, activeJobShortist. An Analytics object will be created by Analytics class, storing the various required data generated, and pass it to Logic and UI for display.
Given below is the sequence diagram for analytics:
3.5. Interviews Feature
3.5.1. Current Implementation
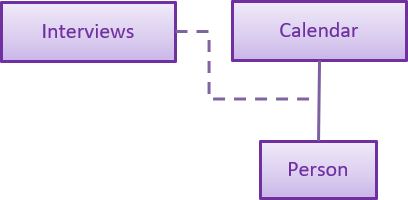
The interviews and its functionalities are facilitated by the Interviews class. It is a private field present in the versionedAddressBook, to facilitate the integration of interviews and its functions with undo/redo operation in slaveFinder(). (Show is not counted as an operation and hence it is not saved as a state). The reason for using Calendar over LocalDate is that in v2.0, the app can be upgrade to schedule interviews for any time instead of only scheduling by days. The Interview class acts as an association class between calendar and person.
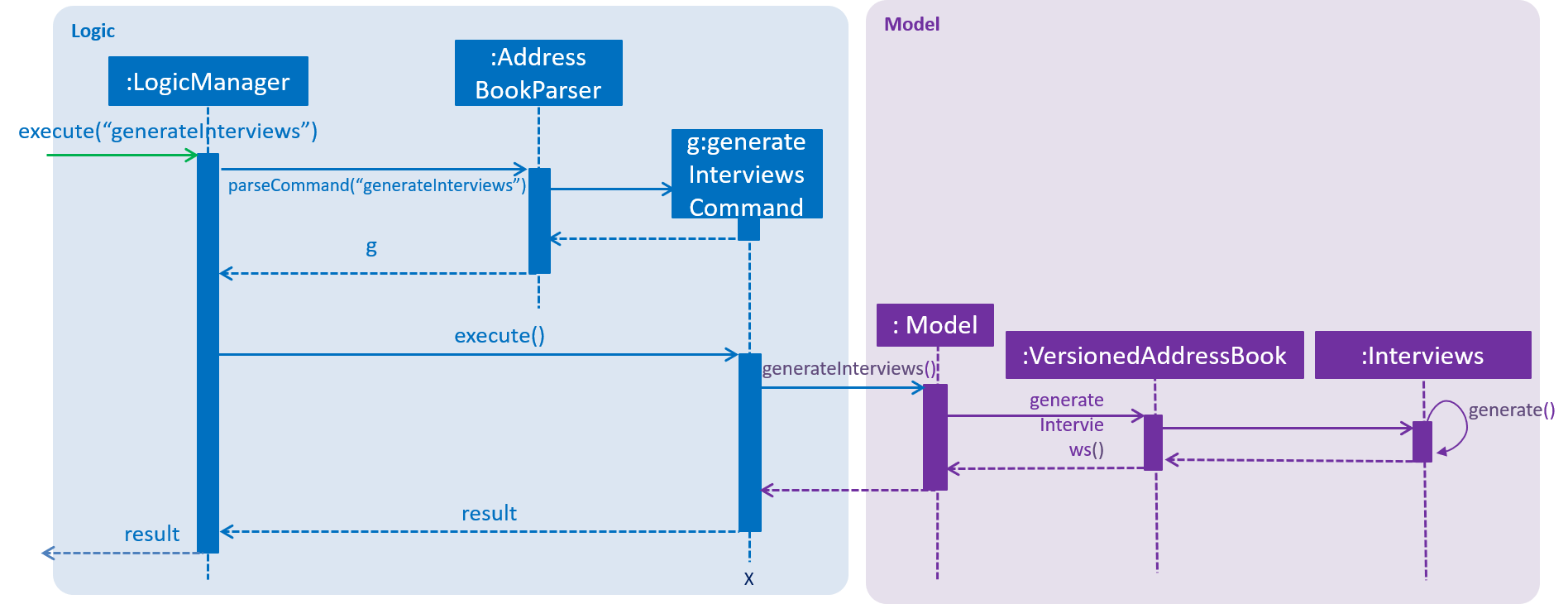
For the generate command. There are total 2 parameters that determines how the interviews list is generated. The 2 parameters are: maxInterviewsADay and blockOutDates. maxInterviewsADay determines the number of interviews that can be scheduled a day and it is saved in the interviews class blockOutDates are the user’s own block out dates which represent unavailable dates that the user is not free and therefore interviews cannot be scheduled. Another thing to note is that weekends are not considered in the scheduled as the user is assumed to have normal working hours from Monday to Friday.
Given below is the sequence diagram for generateInterviews:
An example of generateInterviews:
Step 1. User launches the application. The blockOutDates field in the interviews class is currently empty.
Step 2. User sets the block out dates with setBlockOutDates command. User does not change the max interviews a day and it is set to a default value of 2.
Step 3. User request for interviews to be generated.
Step 4. Interviews are generated with the restriction based on the parameters and working hours of a normal working adult.
Interviews also works with deletePerson, that is, when a person is deleted, he/she is also removed from his/her scheduled interview slots.
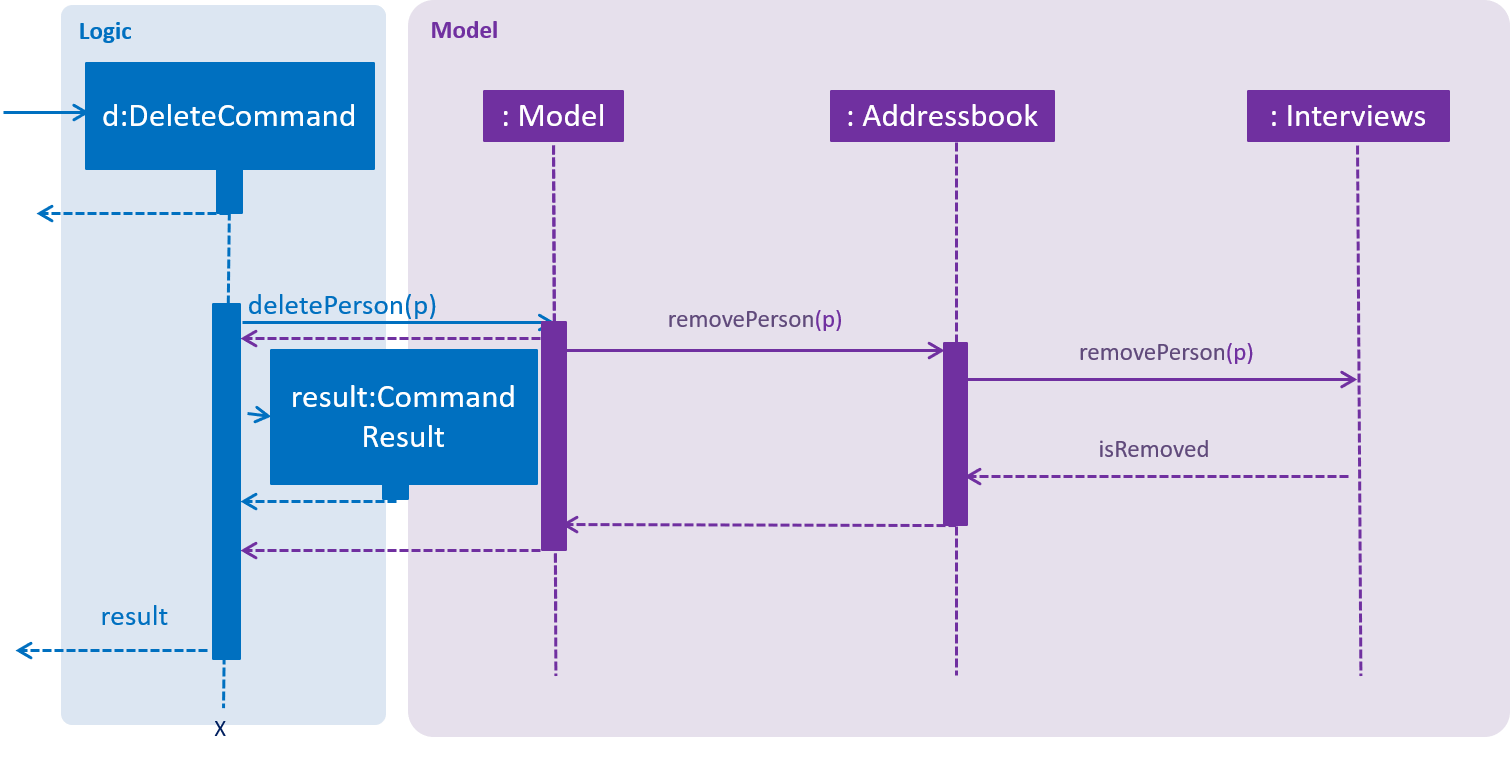
An example of deleting a person:
Step 1. User launches the application and generates interviews.
Step 2. User deletes the person from slaveFinder()
Step 3. Person is removed from his/her scheduled interview date
interviews.removePerson(p) is called. A collection of ArrayList of person is taken from the HashMap and since the collection is backed by the map, any changes to the collection will be reflected in the hashmap. Thus removal of person will be reflected in the hashmap. Therefore this method of removal was used.
Aspect: How interviews is integrated with delete Person command
-
When a person is removed, naturally he/she should also be removed from the scheduled interviews. A remove person function is implemented in interviews which potentially could be used by the v2.0 reschedule command to remove or reschedule persons for interviews.
Aspect: How interviews is integrated with existing undo/redo
-
Alternative 1 (current choice): In order to hinge on the existing undo/redo command, interviews was implemented as a field in AddressBook.java. In the event that undo and redo is called, the data is reset to that of a previous state. In the current implementation, the data is copied over and could take up a lot of time if there is a large amount of dates to copy over.
-
Pros: Easy to implement.
-
Cons: Performance issues may arise in terms of memory usage
-
-
Alternative 2: Implement a function that keeps track of what the user does to interviews and each time a undo is called, the previous command’s inverse function is called.
-
Pros: Less memory is used
-
Cons: Need to consider all possible commands, when adding new command, need to include an inverse command.
-
3.6. [Proposed] Data Encryption
{Explain here how the data encryption feature will be implemented}
3.7. Logging
We are using java.util.logging package for logging. The LogsCenter class is used to manage the logging levels and logging destinations.
-
The logging level can be controlled using the
logLevelsetting in the configuration file (See Section 3.8, “Configuration”) -
The
Loggerfor a class can be obtained usingLogsCenter.getLogger(Class)which will log messages according to the specified logging level -
Currently log messages are output through:
Consoleand to a.logfile.
Logging Levels
-
SEVERE: Critical problem detected which may possibly cause the termination of the application -
WARNING: Can continue, but with caution -
INFO: Information showing the noteworthy actions by the App -
FINE: Details that is not usually noteworthy but may be useful in debugging e.g. print the actual list instead of just its size
3.8. Configuration
Certain properties of the application can be controlled (e.g user prefs file location, logging level) through the configuration file (default: config.json).
4. Documentation
We use asciidoc for writing documentation.
| We chose asciidoc over Markdown because asciidoc, although a bit more complex than Markdown, provides more flexibility in formatting. |
4.1. Editing Documentation
See UsingGradle.adoc to learn how to render .adoc files locally to preview the end result of your edits.
Alternatively, you can download the AsciiDoc plugin for IntelliJ, which allows you to preview the changes you have made to your .adoc files in real-time.
4.2. Publishing Documentation
See UsingTravis.adoc to learn how to deploy GitHub Pages using Travis.
4.3. Converting Documentation to PDF format
We use Google Chrome for converting documentation to PDF format, as Chrome’s PDF engine preserves hyperlinks used in webpages.
Here are the steps to convert the project documentation files to PDF format.
-
Follow the instructions in UsingGradle.adoc to convert the AsciiDoc files in the
docs/directory to HTML format. -
Go to your generated HTML files in the
build/docsfolder, right click on them and selectOpen with→Google Chrome. -
Within Chrome, click on the
Printoption in Chrome’s menu. -
Set the destination to
Save as PDF, then clickSaveto save a copy of the file in PDF format. For best results, use the settings indicated in the screenshot below.
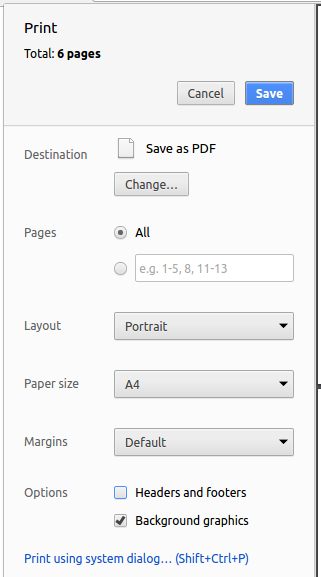
4.4. Site-wide Documentation Settings
The build.gradle file specifies some project-specific asciidoc attributes which affects how all documentation files within this project are rendered.
Attributes left unset in the build.gradle file will use their default value, if any.
|
| Attribute name | Description | Default value |
|---|---|---|
|
The name of the website. If set, the name will be displayed near the top of the page. |
not set |
|
URL to the site’s repository on GitHub. Setting this will add a "View on GitHub" link in the navigation bar. |
not set |
|
Define this attribute if the project is an official SE-EDU project. This will render the SE-EDU navigation bar at the top of the page, and add some SE-EDU-specific navigation items. |
not set |
4.5. Per-file Documentation Settings
Each .adoc file may also specify some file-specific asciidoc attributes which affects how the file is rendered.
Asciidoctor’s built-in attributes may be specified and used as well.
Attributes left unset in .adoc files will use their default value, if any.
|
| Attribute name | Description | Default value |
|---|---|---|
|
Site section that the document belongs to.
This will cause the associated item in the navigation bar to be highlighted.
One of: * Official SE-EDU projects only |
not set |
|
Set this attribute to remove the site navigation bar. |
not set |
4.6. Site Template
The files in docs/stylesheets are the CSS stylesheets of the site.
You can modify them to change some properties of the site’s design.
The files in docs/templates controls the rendering of .adoc files into HTML5.
These template files are written in a mixture of Ruby and Slim.
|
Modifying the template files in |
5. Testing
5.1. Running Tests
There are three ways to run tests.
| The most reliable way to run tests is the 3rd one. The first two methods might fail some GUI tests due to platform/resolution-specific idiosyncrasies. |
Method 1: Using IntelliJ JUnit test runner
-
To run all tests, right-click on the
src/test/javafolder and chooseRun 'All Tests' -
To run a subset of tests, you can right-click on a test package, test class, or a test and choose
Run 'ABC'
Method 2: Using Gradle
-
Open a console and run the command
gradlew clean allTests(Mac/Linux:./gradlew clean allTests)
| See UsingGradle.adoc for more info on how to run tests using Gradle. |
Method 3: Using Gradle (headless)
Thanks to the TestFX library we use, our GUI tests can be run in the headless mode. In the headless mode, GUI tests do not show up on the screen. That means the developer can do other things on the Computer while the tests are running.
To run tests in headless mode, open a console and run the command gradlew clean headless allTests (Mac/Linux: ./gradlew clean headless allTests)
5.2. Types of tests
We have two types of tests:
-
GUI Tests - These are tests involving the GUI. They include,
-
System Tests that test the entire App by simulating user actions on the GUI. These are in the
systemtestspackage. -
Unit tests that test the individual components. These are in
seedu.address.uipackage.
-
-
Non-GUI Tests - These are tests not involving the GUI. They include,
-
Unit tests targeting the lowest level methods/classes.
e.g.seedu.address.commons.StringUtilTest -
Integration tests that are checking the integration of multiple code units (those code units are assumed to be working).
e.g.seedu.address.storage.StorageManagerTest -
Hybrids of unit and integration tests. These test are checking multiple code units as well as how the are connected together.
e.g.seedu.address.logic.LogicManagerTest
-
5.3. Troubleshooting Testing
Problem: HelpWindowTest fails with a NullPointerException.
-
Reason: One of its dependencies,
HelpWindow.htmlinsrc/main/resources/docsis missing. -
Solution: Execute Gradle task
processResources.
6. Dev Ops
6.1. Build Automation
See UsingGradle.adoc to learn how to use Gradle for build automation.
6.2. Continuous Integration
We use Travis CI and AppVeyor to perform Continuous Integration on our projects. See UsingTravis.adoc and UsingAppVeyor.adoc for more details.
6.3. Coverage Reporting
We use Coveralls to track the code coverage of our projects. See UsingCoveralls.adoc for more details.
6.4. Documentation Previews
When a pull request has changes to asciidoc files, you can use Netlify to see a preview of how the HTML version of those asciidoc files will look like when the pull request is merged. See UsingNetlify.adoc for more details.
6.5. Making a Release
Here are the steps to create a new release.
-
Update the version number in
MainApp.java. -
Generate a JAR file using Gradle.
-
Tag the repo with the version number. e.g.
v0.1 -
Create a new release using GitHub and upload the JAR file you created.
6.6. Managing Dependencies
A project often depends on third-party libraries. For example, Address Book depends on the Jackson library for JSON parsing. Managing these dependencies can be automated using Gradle. For example, Gradle can download the dependencies automatically, which is better than these alternatives:
-
Include those libraries in the repo (this bloats the repo size)
-
Require developers to download those libraries manually (this creates extra work for developers)
Appendix A: Product Scope
Target user profile: HR Executive
-
has a need to manage a significant number of job openings and applicants
-
prefer desktop apps over other types
-
can type fast
-
prefers typing over mouse input
-
is reasonably comfortable using CLI apps
Value proposition: manage contacts faster than a typical mouse/GUI driven app
Appendix B: User Stories
Priorities: High (must have) - * * *, Medium (nice to have) - * *, Low (unlikely to have) - *
| Priority | As a … | I want to … | So that I can… |
|---|---|---|---|
|
new user |
see usage instructions |
refer to instructions when I forget how to use the App |
|
HR |
add a new person |
|
|
HR |
delete a person |
reject applicants not suited for the job |
|
HR |
find a person by personal information |
locate details of persons without having to go through the entire list |
|
HR |
filter persons by some specific requirements |
filter out the persons who are not qualified efficiently. |
|
HR |
create a job posting |
have a place to store and keep track of applicants' progress |
|
HR |
move people to the job posting |
start to manage job applications |
|
HR |
move only selected people to jobs and application progress lists |
more easily manage the progress of applications |
|
HR |
view all applicant progress of job application |
know and keep track of who has applied for the job and their progress |
|
HR |
get the best people for a job |
please my boss |
|
HR |
look at the analytics of the job applicants |
to review the quality of job applicants and ensure a better hiring process |
|
HR |
easily store all txt resumes in slaveFinder() |
be more efficient |
|
HR |
arrange interview dates quickly |
to be more efficient in finding the right person for the job |
|
HR |
include block out dates in before scheduling interviews |
to be more efficient in finding the right person for the job |
|
HR |
delete a job posting |
maintain a cleaner interface |
|
HR |
look at the list of applicants I have narrowed down |
send them to boss for approval |
|
HR |
hide private contact details by default |
minimize chance of someone else seeing them by accident |
|
user with many persons in the address book |
sort persons by name |
locate a person easily |
Appendix C: Use Cases
(For all use cases below, the System is the slaveFinder() and the Actor is the user, unless specified otherwise)
C.1. Use case: Delete person
MSS
-
User requests to list persons
-
slaveFinder() shows a list of persons
-
User requests to delete a specific person in the list
-
slaveFinder() deletes the person
Use case ends.
Extensions
-
2a. The list is empty.
Use case ends.
-
3a. The given index is invalid.
-
3a1. AddressBook shows an error message.
Use case resumes at step 2.
-
C.2. Use case: Create and view Job opening
MSS
-
User requests to create a new job
-
slaveFinder() creates the new job
-
User requests to add people to the new job
-
slaveFinder() shows updated job data
-
User requests to view job information
-
slaveFinder() changes view to job display panel
Use case ends.
Extensions
-
2a. Job with name already exists
Use case ends.
-
3a. No people in database
-
3a1. User adds people to database
Use case resumes at step 3.
-
C.3. Use case: Manage people in job opening
MSS
-
User requests to view job information
-
slaveFinder() changes view to job display panel
-
User selects a few people and requests to move them
-
slaveFinder() moves the people and displays updated information
Use case ends.
Extensions
-
2a. Job does not exist
Use case ends.
-
3a. No people in database
-
3a1. User adds people to job
Use case resumes at step 3.
-
C.4. Use case: Generate and show interview dates
MSS
-
User requests to arrange interview dates for applicants in slaveFinder()
-
slaveFinder() assigns to each interviewee a date
-
User request for the interview dates list
Use case ends.
Extensions
-
1a. User wants to set block out dates so no dates are arranged on that day.
-
1a1. Block out dates set using the command.
Use case resumes at step 2.
-
-
1b. User wants to set maximum interviews a day
-
1b1. Max interviews a day set by using the command
Use case resumes at step 2.
-
-
3a. User is not satisfied with the dates
-
3a1. User request to reassign a person to another date
-
3a2. slaveFinder() reassigns that person
-
3a3. slaveFinder() shows the updated interviews dates
Use case ends.
-
C.5. Use case: Clear interview dates
MSS
-
User request to clear interviews
-
slaveFinder() clears interviews
Use case ends.
Extensions
-
3a. User wants to recover the cleared interviews through undo
-
3b. slaveFinder() undos the clear interview operation
-
3c. Previous interview dates are recovered.
Use case ends.
C.7. Use case: Filter person
MSS
-
User requests to list persons
-
slaveFinder() shows a list of persons
-
User requests to filter persons fulfill some requirements in the list
-
slaveFinder() shows a list of target persons
Use case ends.
Extensions
Extensions
-
2a. The list is empty.
Use case ends.
-
3a. The given command is invalid.
-
3a1. slaveFinder() shows an error message.
Use case resumes at step 2.
-
C.8. Use case: View Analytics
MSS
-
User requests to display various lists of applicants from one of the jobs in all job openings lists
-
slaveFinder() shows lists of persons for specific job
-
User requests to view analytics for specific list of persons
-
slaveFinder() shows analytics results
Use case ends.
{More to be added}
Appendix D: Non Functional Requirements
-
Should work on any mainstream OS as long as it has Java
9or higher installed. -
Should be able to hold up to 1000 persons without a noticeable sluggishness in performance for typical usage.
-
A user with above average typing speed for regular English text (i.e. not code, not system admin commands) should be able to accomplish most of the tasks faster using commands than using the mouse.
{More to be added}
Appendix F: Product Survey
Product Name
Author: …
Pros:
-
…
-
…
Cons:
-
…
-
…
Appendix G: Instructions for Manual Testing
Given below are instructions to test the app manually.
| These instructions only provide a starting point for testers to work on; testers are expected to do more exploratory testing. |
For interviews test commands:
-
setMaxInterviewsADay 3
-
setBlockOutDates 22/04/2019 - 24/04/2019
-
generateInterviews
-
showInterviews
-
delete 1 (check that interviews works with delete)
-
showInterviews
-
clearInterviews
-
showInterviews
-
undo (check that interviews works with undo)
-
redo (check that interviews works with redo)
G.1. Launch and Shutdown
-
Initial launch
-
Download the jar file and copy into an empty folder
-
Double-click the jar file
Expected: Shows the GUI with a set of sample contacts. The window size may not be optimum.
-
-
Saving window preferences
-
Resize the window to an optimum size. Move the window to a different location. Close the window.
-
Re-launch the app by double-clicking the jar file.
Expected: The most recent window size and location is retained.
-
{ more test cases … }
G.2. Deleting a person
-
Deleting a person while all persons are listed
-
Prerequisites: List all persons using the
listcommand. Multiple persons in the list. -
Test case:
delete 1
Expected: First contact is deleted from the list. Details of the deleted contact shown in the status message. Timestamp in the status bar is updated. -
Test case:
delete 0
Expected: No person is deleted. Error details shown in the status message. Status bar remains the same. -
Other incorrect delete commands to try:
delete,delete x(where x is larger than the list size) {give more}
Expected: Similar to previous.
-
G.3. Filtering a list of persons
-
Filtering a list of person while All Job Screen show
-
Prerequisites: Using
listcommand to get to All Job Screen. -
Test case:
filter fn/CS m/CS
Expected: All persons with major CS in All Applicants list will show, a filter named "CS" will show on Filter list panel. -
Test case:
filter none
Expected: List unchangeed. Error details shown in the status message. Status bar remains the same. -
Other incorrect filter commands to try:
filter a,filter a fn/CS,filter b fn/CSExpected: Similar to previous.
-
-
Filtering a list of person while Job Detail Screen show
-
Prerequisites: Create a job object using the
createJobcommand. Display job list using theDisplayJobcommand. 4 lists of persons
will show. -
Test case:
filter a fn/CS m/CS
Expected: All persons with major CS in "Applicant" list will show on the Applicant list, a filter named "CS" will show on Filter list panel. -
Test case:
filter none
Expected: List unchangeed. Error details shown in the status message. Status bar remains the same. -
Other incorrect filter commands to try:
filter a,filter fn/CS,filter b fn/CSExpected: Similar to previous.
-
G.4. Saving data
-
Dealing with missing/corrupted data files
-
{explain how to simulate a missing/corrupted file and the expected behavior}
-
{ more test cases … }